Ansible Interview Questions


1. What is Infrastructure as Code?
Infrastructure as code, also referred to as IaC, is an IT practice that codifies and manages underlying IT infrastructure as software. The purpose of infrastructure as code is to enable developers or operations teams to automatically manage, monitor, and provision resources, rather than manually configure discrete hardware devices, operating systems (OSes), applications, and services.
IaC uses higher level or descriptive language to code more versatile and adaptive provisioning and deployment processes. This code is typically written in YAML or JSON.
2. What are the benefits of using IaC?
There are many benefits to using IaC, including:
Cost Reduction: Time-consuming infrastructure configuration, are automated by IaC, the engineers or IT experts can finish these tasks in no time and focus on other mission-critical tasks. This would help minimize costs from necessary tasks and improve other functions according to their demands.Reduced Errors: IaC solves issues as automation reduces the risks of human-made mistakes by cutting down long processes.Improved Security Strategies: With IaC, computing, storage, and networking services are all provisioned with code and deployed the same way, often using a private or public cloud. This can also be the case for security standards. They can be easily created and deployed. This would enhance other strategies as this is a way to avoid security gatekeeper review and approval for almost every security change. This would prove most beneficial for infrastructures requiring tight security, resulting in multiple security passes.Increased Efficiency: There are many processes in building, monitoring, and managing infrastructure structures, but as IaC has made it possible to automate almost every process, the work can be two times faster. Automation stretches from significant procedures like virtualization to user account management, databases, network management, and even minor operations like adding environments and resources when needed or shutting down when it is not the case. This automation feature promises faster and simpler procedures.Improved Consistency: IaC improves consistency during the activities like deployment and configuration by preventing waste of valuable resources, unwanted downtime, and setbacks that can cause inconsistencies in the configuration. These inconsistencies can be challenging to remove when discovered.Self Documentation: IaC creates detailed reports and documentation of every process. For example, When employees leave a company or a person is setting up the code model for another person, IaC documents every action, process, and change. IaC also tracks and tests every configuration like a code. This documentation can be a yardstick for a new employee or configuration manager.Eliminate Configuration Drift: This implies that one can deploy the code many times, with the first deployment being the actual deployment and subsequent deployments having no essential effect.
3. How does IaC work?
Three defining steps are the working principles of IaC in every use case. These steps are:
A developer writes the specifications for the infrastructure in a domain-specific language.
The files containing the specifications are sent to a master server, code repository, or a management API.
With those specifications, the platform creates and configures the computer’s resources with some steps.
4. What are different types of IaC?
There are four different types of infrastructure as code, and each is used according to the needed situation:
Scripts: Scripting is a very direct form of IaC. This type of IaC is usually used for simple or one-off tasks and is not advised for complex tasks.Configuration Management Tools: These tools implement automation by installing and configuring servers. This type of IaC is designed for complex tasks as they are specialized tools built to manage software. They are the most common type of IaC; examples are Ansible, chef, etc.Provisioning Tools: This type of IaC has more advantages in complex tasks. These tools implement automation by creating infrastructure. Developers use this type of IaC to create infrastructure components. Common examples of some provisioning tools are OpenStack heat and AWS CloudFormation.Containers and Templating Tools: These tools formulate templates and images pre-loaded with all the libraries and components required to run an application. Data distributed with these tools are easy to manage and have a lower overhead compared to running an entire server. However, container security may be a concern.
5. What is Configuration Management?
Configuration management (CM) is the practice of maintaining computer systems in a consistent and desirable state. The CM team tracks and manages your organization's software and hardware assets to ensure they are working optimally and are up to date.
6. What are the features of Configuration Management?
Some of the features of Configuration Management are:
Increased Consistency: CM ensures that development, test, and production environments are consistent in your organization. It helps ensure that deployed applications behave in the manner that is expected of them and reduce the risk of errors.Increased security: CM can help to identify and track security vulnerabilities. This can help to prevent unauthorized access to systems and data.Increased compliance: CM can help organizations to comply with regulatory requirements. This can help to avoid fines and penalties.Greater Efficiency: Configuration management helps automate the deployment process, reducing the time and effort required to deploy software.Improved Collaboration: Configuration management tools help bring together development and operations teams, enabling them to work collaboratively and deliver software more efficiently.Disaster Recovery: If the worst does happen, configuration management ensures that our assets are easily recoverable. The same applies to rollbacks. Configuration management makes it so that when we’ve put out bad code, we can go back to the state of our software before the change.Easier Scaling: Provisioning is the act of adding more resources (usually servers) to our running application. Configuration management ensures that we know what the good state of our service is.
7. What is the difference between IaC and Configuration Management?
Below is the screenshot of the difference between IaC and CM: -

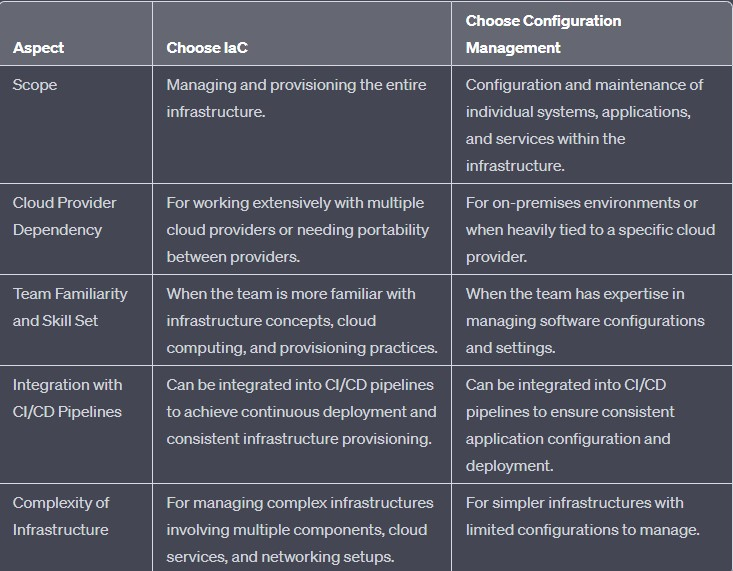
8. When to choose IaC and when to choose Configuration Management?
A small tabular form to choose which one of the above two: -
9. What are the tools used for IaC and Configuration Management?
Tools used for IaC are: -
Terraform
AWS CloudFormation
3. Azure Resource Manager (ARM)
4. Google Cloud Deployment Manager
Tools used for Configuration Management are: -
Ansible
Chef
Puppet
10. How does Configuration Management Work?
There are basically four steps involved: -
Identification: The first action towards configuration management is information gathering. Configuration data should be aggregated and compiled from different application environments, development, staging, and production for all the components and services in use. Any secret data like passwords and keys should be identified and securely encrypted and stored. At this point configuration data should be organized into data files that can be pointed to as a central source of truth.Baseline: After configuration data has been aggregated and organized a baseline can be established. A baseline configuration is a known state of configuration that will successfully operate the dependent software without error. This baseline is usually created by reviewing the configuration of a functioning production environment and committing those configuration settings.Version Control: Your development project should use a version control system. If not, install Git, initialize a repository for the project, and add the configuration data files to the repository. A word of caution before adding configuration data to a repository: make sure that any secret data like passwords or keys are encrypted with an external key. Secret data accidentally committed to a repository is a huge risk. It needs to be scrubbed from the repositories history or it will be at risk of being exploited.Auditing: Having configuration data organized and added to a repository enables collaboration and visibility into the system’s configuration. The popular pull request workflow that software teams use to review and edit code can then be applied to configuration data files. This helps build out an audit and accounting system. Any changes applied to the configuration must be reviewed and accepted by the team. This adds accountability and visibility into configuration changes.
11. What is Ansible and why it’s the most popular tool in DevOps?
Ansible is an open-source IT automation platform from Red Hat. It enables organizations to automate many IT processes usually performed manually, including provisioning, configuration management, application deployment, and orchestration.
It’s popular in DevOps due to its agentless architecture, simplicity, wide platform support, scalability, idempotency, integration capabilities, and active community.
With its human-readable syntax and extensive ecosystem, Ansible enables efficient and streamlined automation of repetitive tasks, making it a preferred choice for DevOps practitioners.
12. How Ansible is different from Puppet?
Ansible and Puppet are both configuration management tools used in DevOps.
Ansibleuses an agentless architecture, communicates via SSH, and employs a YAML-based syntax for playbooks.Puppetuses an agent-based architecture, relies on a central Puppet master, and employs a declarative Puppet language.Ansibleemphasizes simplicity and ease of use, whilePuppetoffers more advanced features for complex configurations and a stronger focus on state enforcement.Ansibleuses the Push model, whilePuppetusing Push Model.
Withpush architecture, servers can simply push messages and client details to the queue together, making push architecture a viable option in a complex system. In a pull architecture, servers have to go through complex logic to check and pull a message out of another server and into a queue.
13. Can you list down the pros and cons of Ansible?
✅ Pros of Ansible: -
Agentless architecture.
Simple and easy-to-understand syntax.
Wide platform support.
Scalable and efficient.
Idempotent execution.
Strong integration capabilities.
Active community and extensive ecosystem.
❗️ Cons of Ansible: -
Slower execution compared to agent-based tools.
Limited support for complex configurations.
Lack of built-in reporting and monitoring.
Reliance on SSH connectivity for communication.
Limited support for Windows environments (compared to Linux).
14. How does Ansible work?
There are mainly two computer categories in Ansible: the managed node and the control node.
The control node, a computer, is responsible for running Ansible. At least one control node should be there; a backup control node may also exist in parallel. A managed node can be any device managed by the control node.
Ansible’s standard operating procedure is that it first gets connected to nodes such as servers, clients, or anything that needs to be configured and then sends a small program known as the Ansible module to that node. Then these modules are executed by Ansible over SSH, which is removed when the execution is completed.
The important thing for this interaction is that Ansible control nodes must have login access to the managed nodes. The SSH keys provide this access, and other forms of authentication also provide helping hands.
15. What is the minimum requirement for Ansible to work?
Currently, Ansible can be run from any machine with Python 2 (versions 2.6 or 2.7) or Python 3 (versions 3.5 and higher) installed (Windows isn’t supported for the control machine). This includes Red Hat, Debian, CentOS, OS X, any of the BSDs, and so on.
16. Explain dynamic inventory and its use cases in Ansible.
Dynamic inventory in Ansible refers to the ability to generate inventory information dynamically at runtime.
Instead of relying on a static inventory file, dynamic inventory sources can be scripts, APIs, or external systems.
It allows for automatically discovering and provisioning hosts, making it useful for dynamic or cloud-based environments, auto-scaling scenarios, and managing large-scale infrastructures where hosts may change frequently.
17. Which protocol does Ansible use to communicate with Linux & Windows?
For Linux, the protocol used is SSH.
For Windows, the Protocol is used in WinRM.
18. What are Ansible Modules?
Ansible modules are reusable units of code that perform specific tasks or actions within Ansible playbooks. They encapsulate functionality such as managing files, executing commands, configuring services, and interacting with various systems and platforms.
Modules can be written in any programming language and are used to define the desired state and perform actions on managed hosts during Ansible automation tasks.
19. What are Ansible Tasks?
In Ansible, a task is a unit of work defined in a playbook that performs a specific action on a target host. Tasks are executed sequentially and can include commands, module invocations, or even include other tasks.
They define the desired state and actions to be taken to achieve that state, such as installing packages, configuring services, or managing files on the managed hosts.
20. Can you explain what is a playbook in Ansible?
Ansible Playbooks offer a repeatable, reusable, simple configuration management and multi-machine deployment system, one that is well suited to deploying complex applications. If you need to execute a task with Ansible more than once, write a playbook and put it under source control. Then you can use the playbook to push out new configurations or confirm the configuration of remote systems.
An Ansible playbook can be defined as a configuration file written in YAML to provide instructions for things that need to be done to bring a managed node into the required state.
In other words, A playbook is a list of plays which runs in order from top to bottom. Within each play, tasks also run in order from top to bottom. Playbooks with multiple ‘plays’ can orchestrate multi-machine deployments, running one play on your webservers, then another play on your database servers, then a third play on your network infrastructure, and so on.
Play refers to the set (one or more) of actions (tasks) you want to execute on a set (one of more) of hosts.
21. How do Handlers work in task execution in Ansible?
Handlers in Ansible are tasks that are triggered only when notified by other tasks. They are typically used to handle specific events or changes in the system, such as service restarts or configuration updates.
Handlers are defined separately from tasks and can be triggered using the “notify” keyword. When notified, handlers are executed at the end of the playbook run to ensure consistency and order in task execution.
22. What are Ansible Roles?
Roles in Ansible provides a framework for collections of variables, files, tasks, modules, and templates that are independent or interdependent.
In Ansible, the role is a primary mechanism to break a playbook into multiple files. Ansible makes complex playbook writing simple and can be reused easily. The purpose of breaking the playbook is carried out so that it can be into reusable components. Each role is assigned a particular functionality for the desired output.
Roles are small functionality within playbooks that peak it can be independently used. In any conditions, you can not execute the role directly.
23. Can you explain what is Ad-Hoc command in Ansible?
An Ansible ad-hoc command uses the /usr/bin/ansible command-line tool to automate a single task on one or more managed nodes. ad-hoc commands are quick and easy, but they are not reusable.
Ansible ad-hoc commands are idempotent—i.e., the state of the node is checked before executing the command, and if no state change can occur, the command isn’t executed.
Ad-hoc commands are executed in parallel by default, enabling rapid execution across multiple hosts.
24. What is Ansible Vault?
Ansible Vault is a feature in Ansible that provides secure encryption and decryption of sensitive data such as passwords, API keys, and other secrets. It allows users to encrypt files or individual variables within playbooks, protecting them from unauthorized access.
Vault ensures that sensitive information remains secure and can be safely stored and shared within an Ansible project.
25. Can you explain the concept of Blocks in Ansible?
Blocks in Ansible provides a way to group related tasks together and apply error-handling and exception-handling logic. They allow for logical organization and control flow within a playbook. Tasks within a block are executed sequentially, and if any task fails within the block, error-handling strategies can be defined, such as retrying the block or moving to a specific rescue block for error handling.
26. What are Groups of Groups and Group Variables in Ansible?
In Ansible, groups of groups (also known as nested groups) allow for hierarchical organization of hosts into logical groups. It enables grouping hosts based on different criteria, such as environment or role.
Group variables, on the other hand, are variables specific to a group or groups of hosts. They provide a way to set shared variables that can be accessed by all hosts within a group, simplifying configuration management.
27. Do you have any idea how to turn off the facts in Ansible?
To turn off gathering facts in Ansible, you can use the gather_facts directive in your playbook. Set gather_facts: no at the playbook level to disable facts gathering for all hosts within the playbook.
Alternatively, you can set gather_facts: no at the task level to disable facts gathering for specific tasks, allowing for more granular control over when facts are collected during playbook execution.
28. How are variables merged in Ansible?
In Ansible, variable merging follows a specific order of precedence.
Variables are merged in the following order: the highest priority is given to variables defined in the playbook or role defaults, then variables defined in inventory files, followed by variables defined in playbook vars, and finally, variables defined in host or group vars.
This merging process ensures that variables are resolved based on their defined scope and priority.
29. What are Cache Plugins in Ansible? Any idea how they are enabled?
Cache plugins in Ansible are used to cache gathered facts, playbook results, and other data to improve performance by reducing the need for re-execution.
They can be enabled by configuring the ansible.cfg file and specifying the cache plugin to use.
Ansible provides various cache plugins, such as Redis, Memcached, JSON, and more, allowing users to choose the most suitable caching mechanism for their environment.
30. What are Registered Variables in Ansible?
Registered variables in Ansible are used to capture and store the output or results of a task for later use within the playbook. When a task is executed, the result can be saved to a variable using the register keyword.
The registered variable can then be accessed and utilized in subsequent tasks or conditionals, enabling more complex workflows and decision-making based on task outcomes.
31. How does the Network Module work in Ansible?
The Network module in Ansible provides a collection of modules specifically designed for managing network devices, such as routers, switches, and firewalls.
These modules communicate with network devices using protocols like SSH, Telnet, or APIs. They allow for tasks like configuring interfaces, managing VLANs, updating access control lists (ACLs), and more, providing a streamlined and consistent approach to network automation within Ansible playbooks.
32. How Ansible manage multiple communication protocols?
Ansible manages multiple communication protocols by leveraging the concept of connection plugins. Connection plugins are responsible for establishing the communication between the Ansible control node and the target hosts.
Ansible provides a range of connection plugins that support various protocols like SSH, WinRM, and local connections.
By configuring the appropriate connection plugin, Ansible can seamlessly manage hosts with different communication requirements.
33. How to handle different machines needing different user accounts or ports to log in with using Ansible?
To handle different machines needing different user accounts or ports for logging in with Ansible, you can utilize the ansible_user and ansible_port variables in your inventory or playbook.
In the inventory file, specify the respective user account and port for each machine. Alternatively, you can define these variables directly in the playbook using the vars section. Ansible will then use the specified user account and port when connecting to the corresponding machines during execution.
34. How to see a list of all of the ansible variables?
To see a list of all Ansible variables, you can use the debug module with the msg parameter set to {{vars}} in your playbook.
This will print the entire set of variables and their values for the specific host being targeted. When executing the playbook, you will see the list of all Ansible variables in the output for that host.
3️5. How to create an AWS EC2 key using Ansible?
To create an AWS EC2 key pair using Ansible, you can use the ec2_key module. Here's an example playbook:
- name: Create EC2 Key Pair
hosts: localhost
gather_facts: false
tasks:
- name: Create EC2 Key Pair
ec2_key:
name: my-key
region: us-east-1
register: keypair
- name: Save private key to file
copy:
content: "{{ keypair.key.private_key }}"
dest: /path/to/private/key.pem
mode: 0600
In this example, the ec2_key module creates a key pair with the name "my-key" in the specified region. The private key of the created key pair is then saved to a file using the copy module. Adjust the values according to your desired key name, region, and file destination.
36. How to upgrade the Ansible version to the latest version?
One can easily upgrade the Ansible version to the specific version using the below one-liner command:
sudo pip install ansible==<version-number>
37. How to install a WordPress application inside a Docker container using Ansible?
To install WordPress inside a Docker container using Ansible, you can utilize Ansible’s Docker modules. Here’s an example playbook:
- name: Install WordPress in Docker
hosts: localhost
gather_facts: false
tasks:
- name: Create a network for containers
docker_network:
name: wordpress_network
- name: Start MySQL container
docker_container:
name: mysql_db
image: mysql:latest
env:
MYSQL_ROOT_PASSWORD: mysecretpassword
networks:
- name: wordpress_network
- name: Start WordPress container
docker_container:
name: wordpress_app
image: wordpress:latest
env:
WORDPRESS_DB_HOST: mysql_db
WORDPRESS_DB_PASSWORD: mysecretpassword
ports:
- "8080:80"
networks:
- name: wordpress_network
In this example, the playbook creates a network using the docker_network module. It then starts a MySQL container using the docker_container module, specifying the necessary environment variables. Finally, it starts a WordPress container with the appropriate environment variables and port mapping. Adjust the container names, network names, environment variables, and ports as per your requirements.
38. How to generate encrypted passwords for the user module in Ansible?
To generate encrypted passwords for the user module in Ansible, you can use the mkpasswd command-line tool available in most Linux distributions. Here's an example:
Open a terminal on your Ansible control node.
Run the following command to generate an encrypted password:
cssCopy codemkpasswd --method=SHA-512
39. How to keep secret data in my playbook in Ansible?
To keep secret data secure in your playbook, you can use Ansible Vault. Vault allows you to encrypt sensitive information such as passwords, API keys, and credentials.
You can create an encrypted vault file with the ansible-vault command and reference the encrypted values in your playbook. During playbook execution, Ansible will prompt the vault password to decrypt the sensitive data.
40. What is the minimum requirement for using Docker modules in Ansible?
To use Docker modules in Ansible, you need the following minimal requirements:
Ansible version 2.1 or later installed on the control node.
Docker is installed on the target hosts where you want to manage containers.
Network connectivity between the control node and the target hosts. With these prerequisites met you can use Ansible’s Docker modules to manage Docker containers and images from your Ansible playbooks.
41. How does the Ansible module connect to Docker API?
Ansible connects to the Docker API using the Docker SDK for Python. The Docker modules in Ansible utilize this SDK to interact with the Docker daemon on the target host.
The Docker SDK communicates with the Docker API over HTTP or a Unix socket, allowing Ansible to perform actions such as managing containers, images, networks, and volumes using the Docker API endpoints.
42. What’s Ansible Tower? What are its features?
Ansible Tower is a web-based solution that makes it simply accessible by IT teams. The principle function of Ansible is to behave as the hub for all automation duties. The tower can be utilized without cost for as much as 10 nodes.
Below are some of the primary features of Ansible tower: -
Job Scheduling.
It helps to schedule the roles to run later and set options for repetition.
Roll-based mostly Action Control: You may simply arrange different roles and supply entry to specific roles utilizing Ansible tower.
Totally Documented REST API: Utilizing REST API, you’ll be able to simply combine Ansible together with your already existing environment.
Portal Mode: Ansible Tower provides an easy to make use of UI, which is beneficial for each beginner and experienced customers.
Cloud Integration: Ansible Tower has compatibility with many of the Cloud Environments corresponding to Azure, Rackspace, and Amazon EC2.
43. What’s Ansible Galaxy?
Ansible Galaxy is a storehouse of various Ansible roles via which you’ll be able to share the content securely. It will get done by way of the Galaxy website, which lets the users find and share the content as per the role entry.
Ansible-Galaxy is the command that you should utilize to put in the role, create a brand new role, take away the already present role, and carry out different tasks on the Galaxy website.
44. Explain Ansible architecture.
Ansible automation engine is the main component of Ansible, which interacts directly with the configuration management database, cloud services, and various users who write playbooks to execute it.
The below figure depicts the Ansible architecture:
The following are the components of the Ansible Automation engine:
Modules: Ansible works effectively by connecting nodes and pushing out scripts called "Ansible modules". It helps to manage packages, system resources, files, libraries, etc.Inventories: These are the lists of nodes or hosts containing their databases, servers, IP addresses, etc.APIs: These are used for commuting public or private cloud services.Plugins: Plugins augment Ansible's core functionality. Also offers extensions and options for the core features of Ansible - transforming data, connecting to inventory, logging output, and more.Playbooks: Describes the tasks that need to be executed. They are simple code files written in YAML format and can be used to declare configurations, automate tasks, etc.Hosts: Hosts are node systems that are automated by Ansible on any machine like Linux, RedHat, Windows, etc.Networking: Ansible can be used to automate multiple networks and services. It uses a secure and simple automation framework for IT operations and development.Cloud: A system of remote servers that allows you to store, manage, and process data, rather than a local server.CMDB: It is a type of repository which acts as a data warehouse for IT installations.